ProActive Quickstart - Deep Learning Workflows
ProActive AI Orchestration (PAIO) is an interactive graphical interface that enables developers and data scientists to quickly and easily build, train, and deploy machine learning models at any scale. It provides a rich set of generic machine learning tasks that can be connected together to build basic and complex machine learning/deep learning workflows for various use cases such as: fraud detection, text analysis, online offer recommendations, prediction of equipment failures, facial expression analysis, etc. These tasks are open source and can be easily customized according to your needs. PAIO can schedule and orchestrate executions while optimising the use of computational resources. Usage of resources (e.g. CPU, GPU, local, remote nodes) can be quickly monitored.
This tutorial will show you how to:
- Build a deep learning workflow for sentiment analysis using generic deep learning tasks
- Submit it to the scheduler and monitor its execution.
- Visualize and download the prediction results.
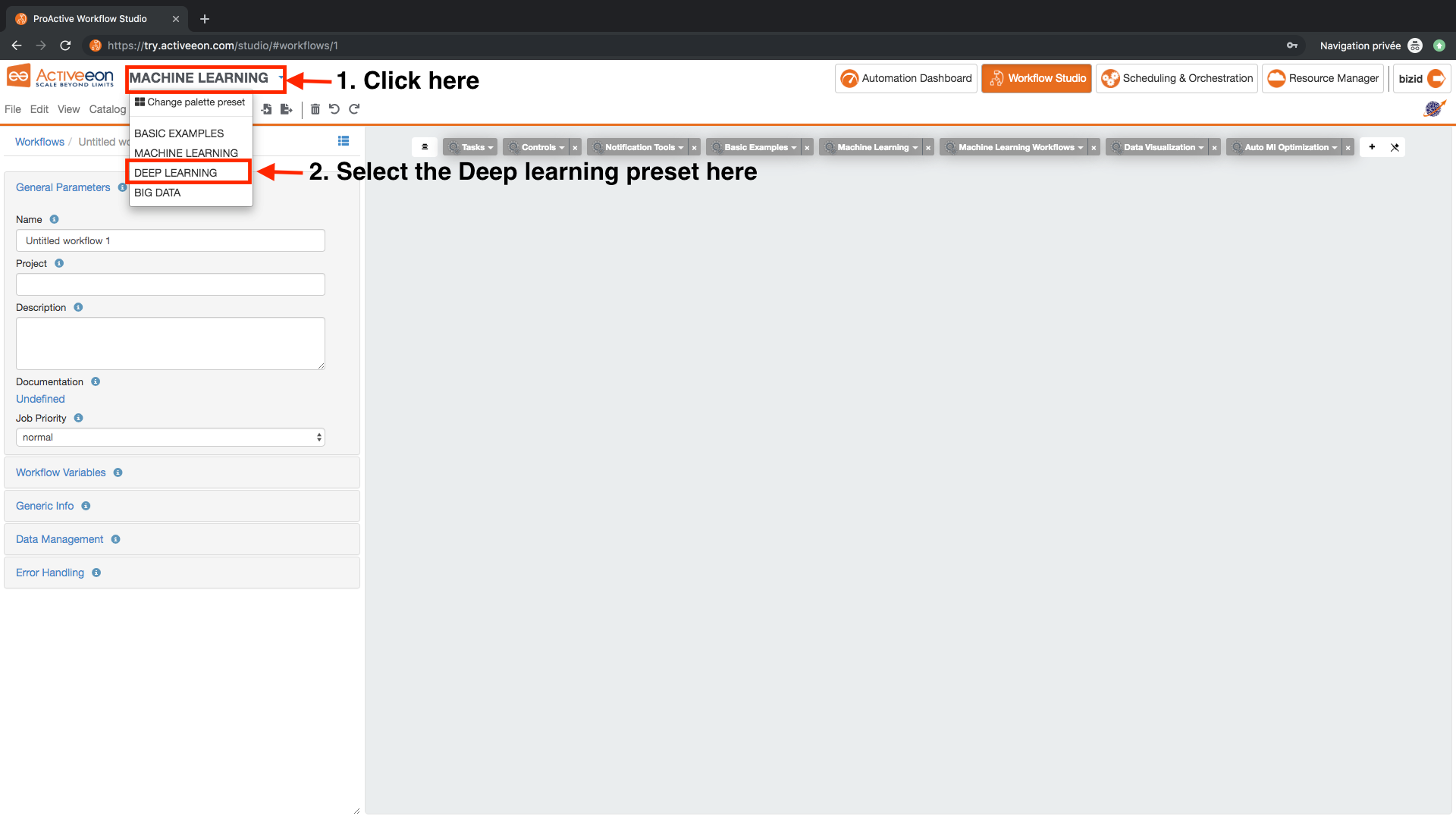
1 Customize the Canvas
Customize the canvas in order to use the buckets related to deep learning:
- Open ProActive Workflow Studio home page.
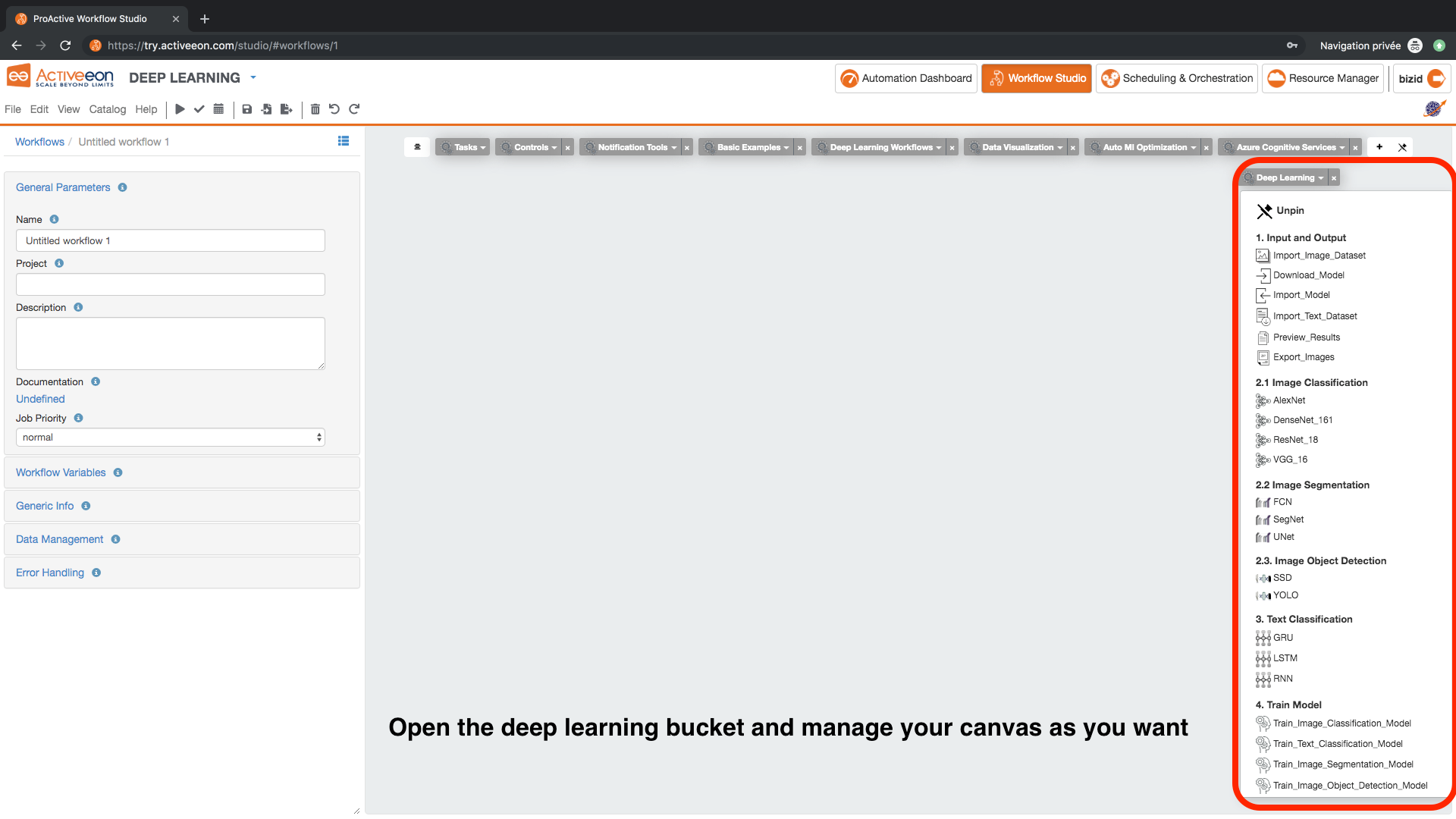
- Change the palette preset to DEEP LEARNING.
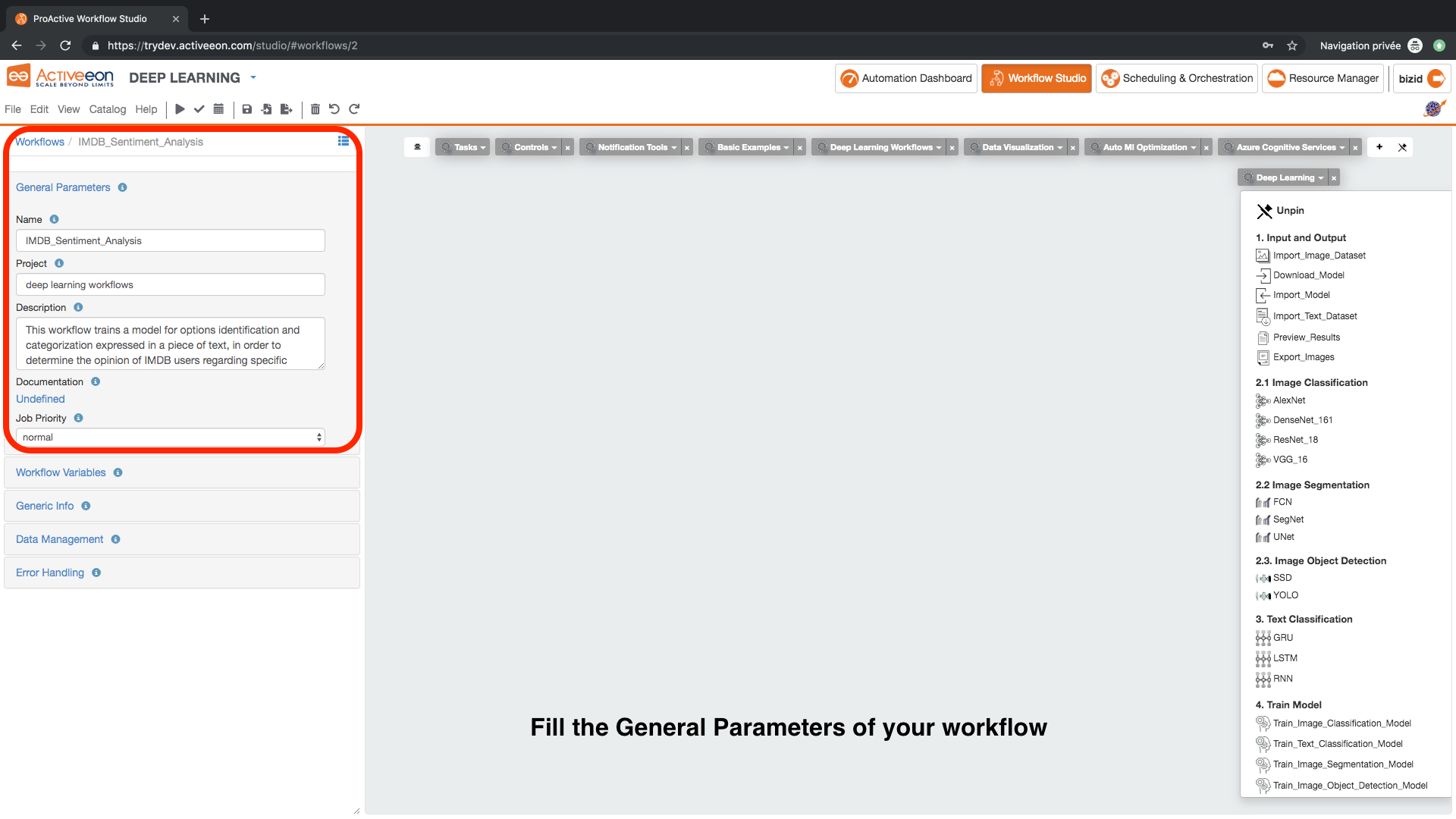
- Fill the General Parameters of the workflow.
2 Build a Sentiment Analysis Workflow
- Drag and drop the following tasks from each bucket:
- Deep Learning Bucket:
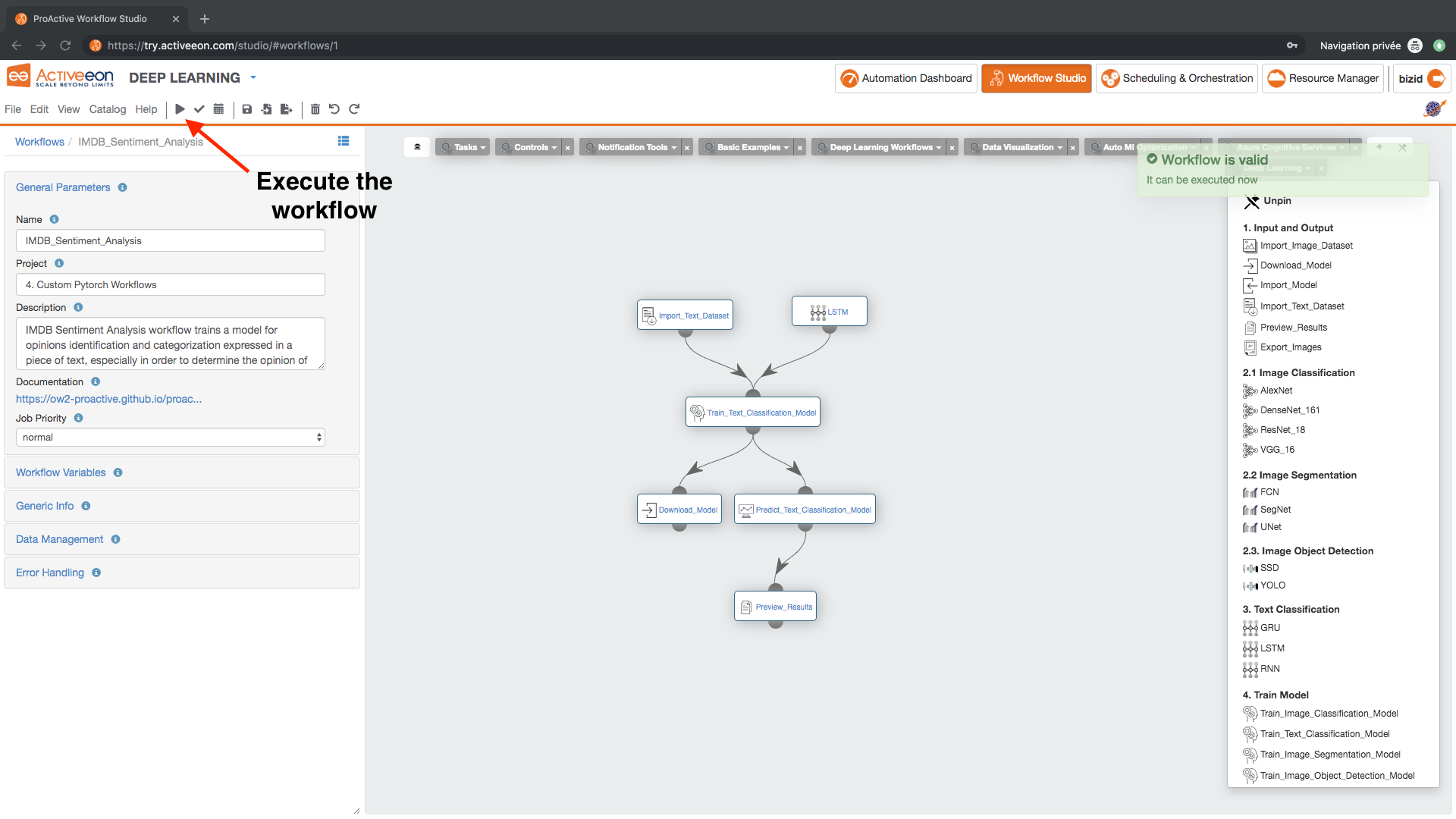
Import_Text_Dataset task from 1. Input and Output. This task imports and splits any data stored in a specified structure as explained in the documentation into training, validation and test datasets. It uses by default the IMDB dataset uploaded from this link: https://s3.eu-west-2.amazonaws.com/activeeon-public/datasets/IMDB.zip. This dataset is adapted for sentiment analysis use cases.
LSTM task from 3. Text Classification. This task specifies the deep learning algorithm that will be used for training the model.
Train_Text_Classification_Model task from 4. Train_Model. This task trains a predictive model using the training dataset and based on the chosen algorithm.
Predict_Text_Classification_Model task from 5. Predict. This task specifies the algorithm that will be used for training the model.
Download_Model task from 1. Input and Output. This task downloads the trained model.
Preview_Results task from 1. Input and Output. This task exports the prediction results.
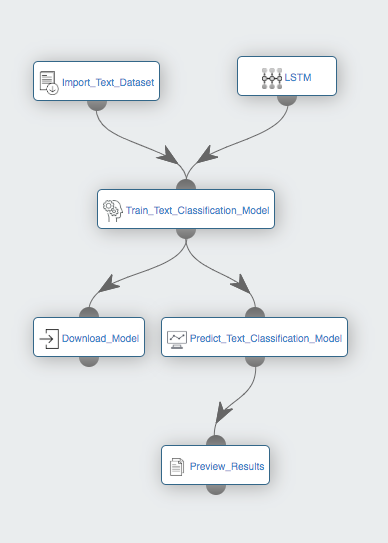
- Link the different Workflows in a way that you will have the following workflow:
- Set the variables of each task according to your needs. For example:
- Select the Import_Text_Dataset task and change the value of the following variables in order to use 70% of the dataset for training and the remaing data for validation and test:
TRAIN_SPLIT: 0.7
TEST_SPLIT: 0.2
VALIDATION_SPLIT: 0.1
- Select the Train_Text_Classification_Model and change the value of the following variables in order to have a more efficient model:
EPOCHS: 20
3 Submit and Visualize Results
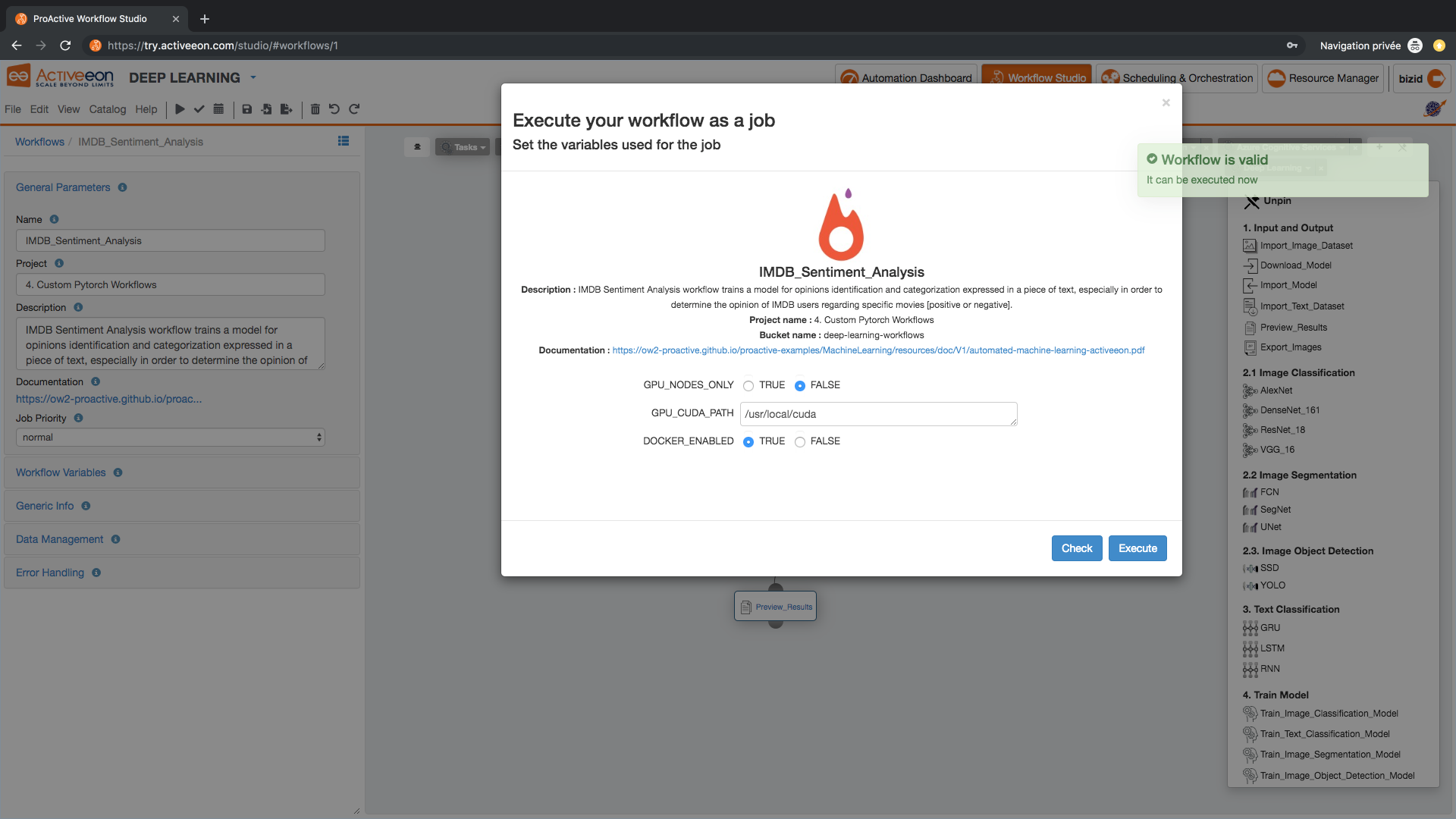
- Press Execute and keep the following default workflow variables in the workflow variables dialog box:
- DOCKER_ENABLED: True
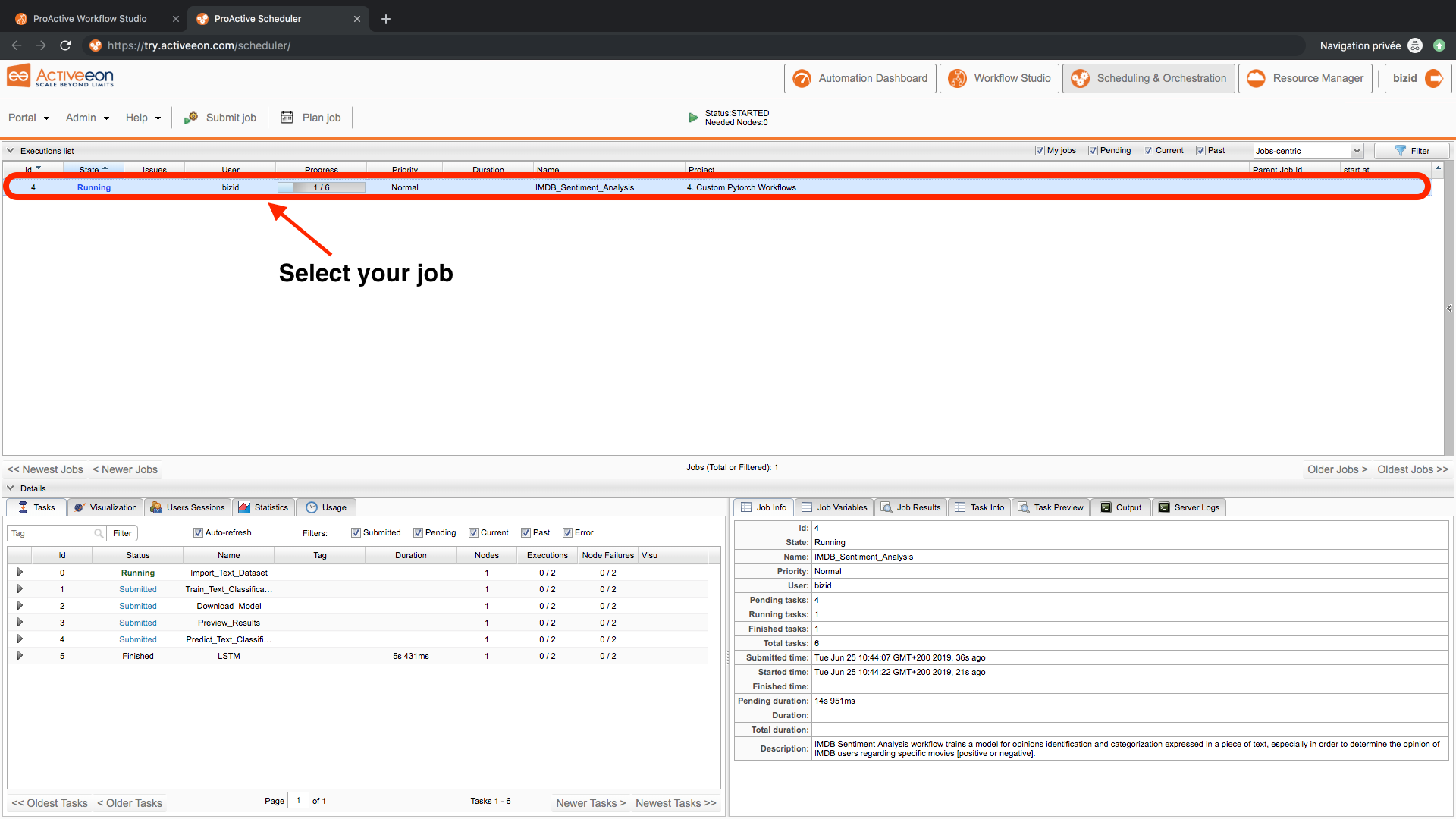
- Open the Scheduling & Ochestration Page and Select the submitted job to view detailed information about the tasks, the output, the execution times, and more.
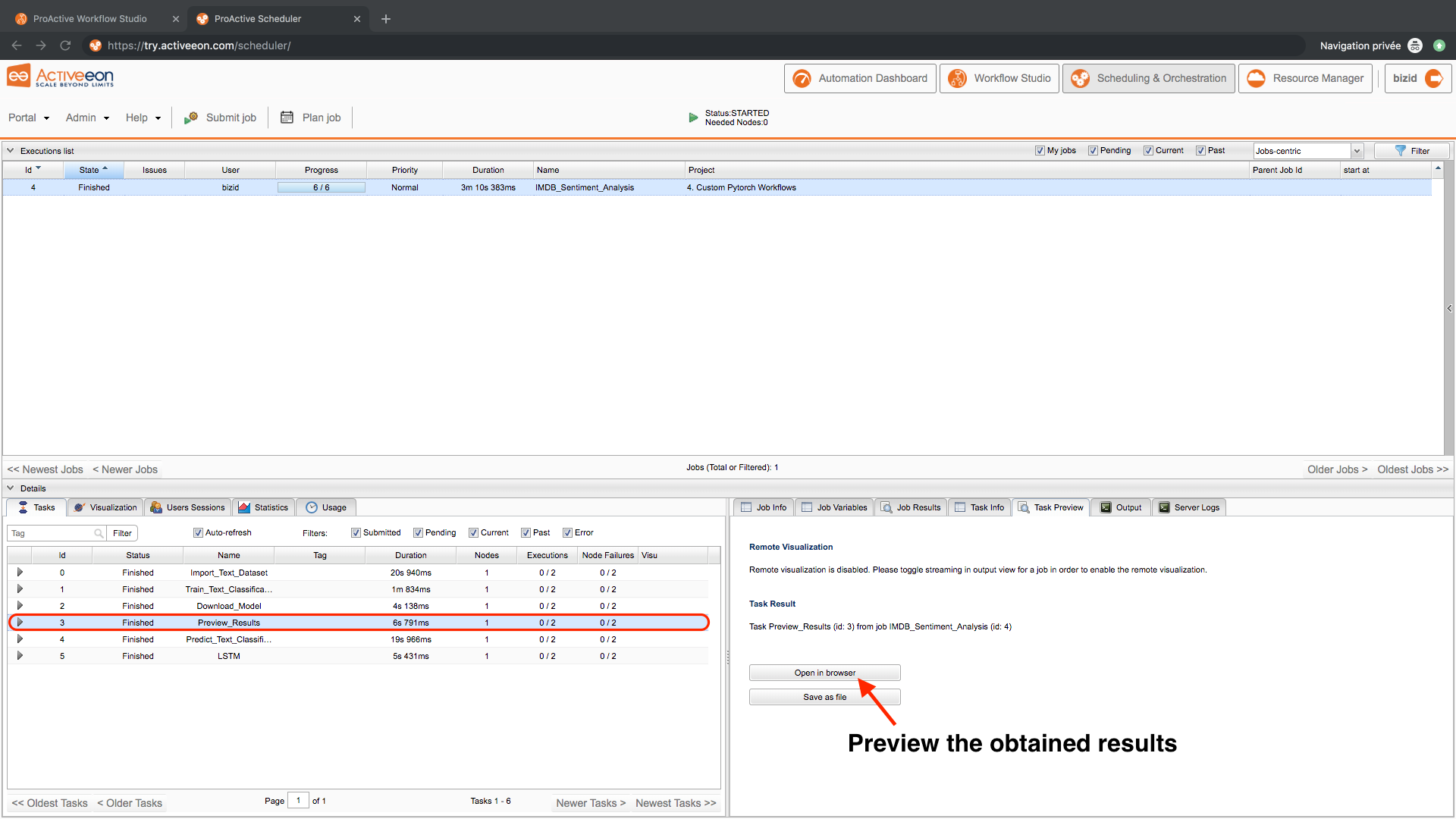
- Check the results:
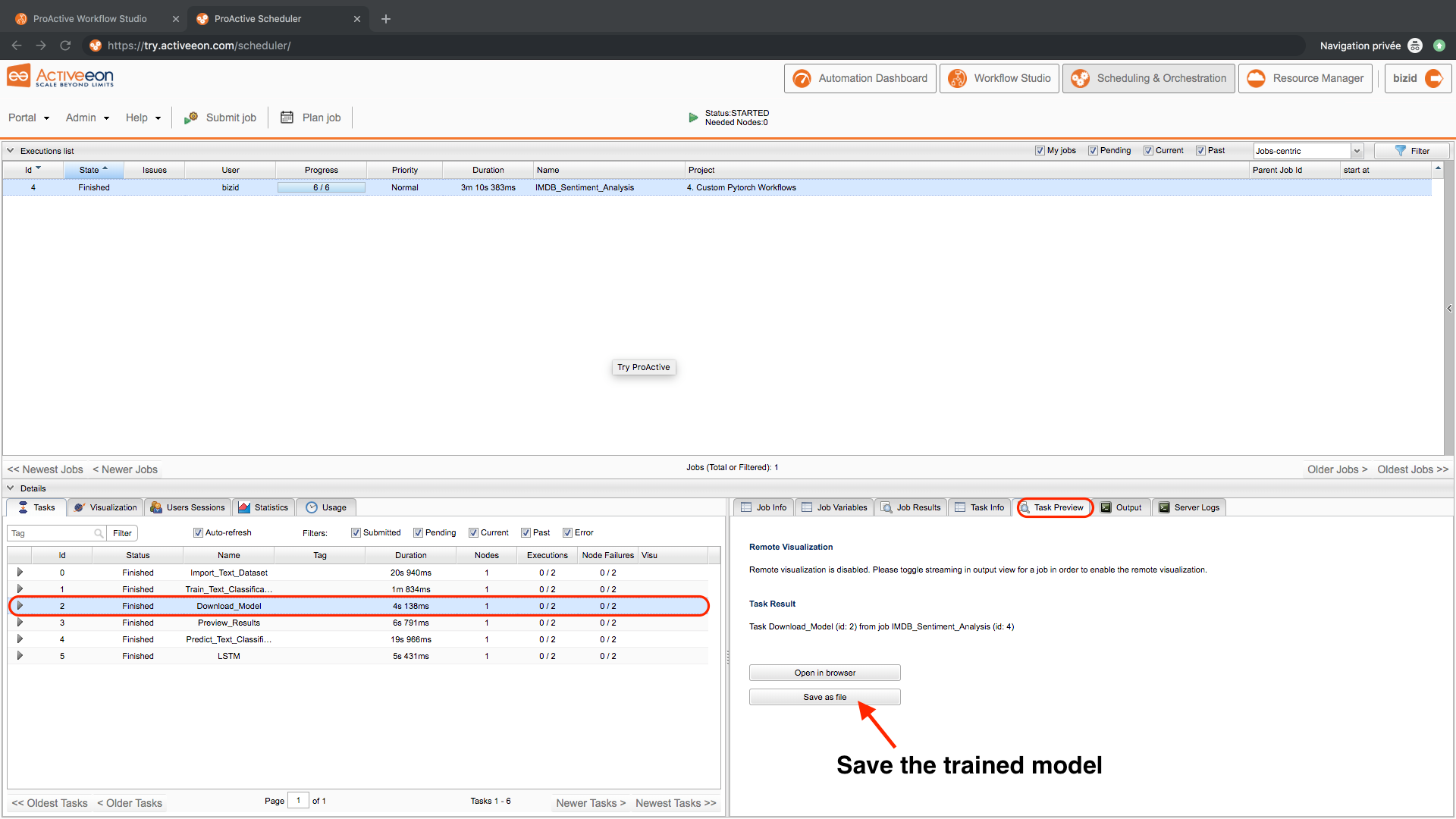
- Click on the Download_Model task then click save as file to download the trained model.
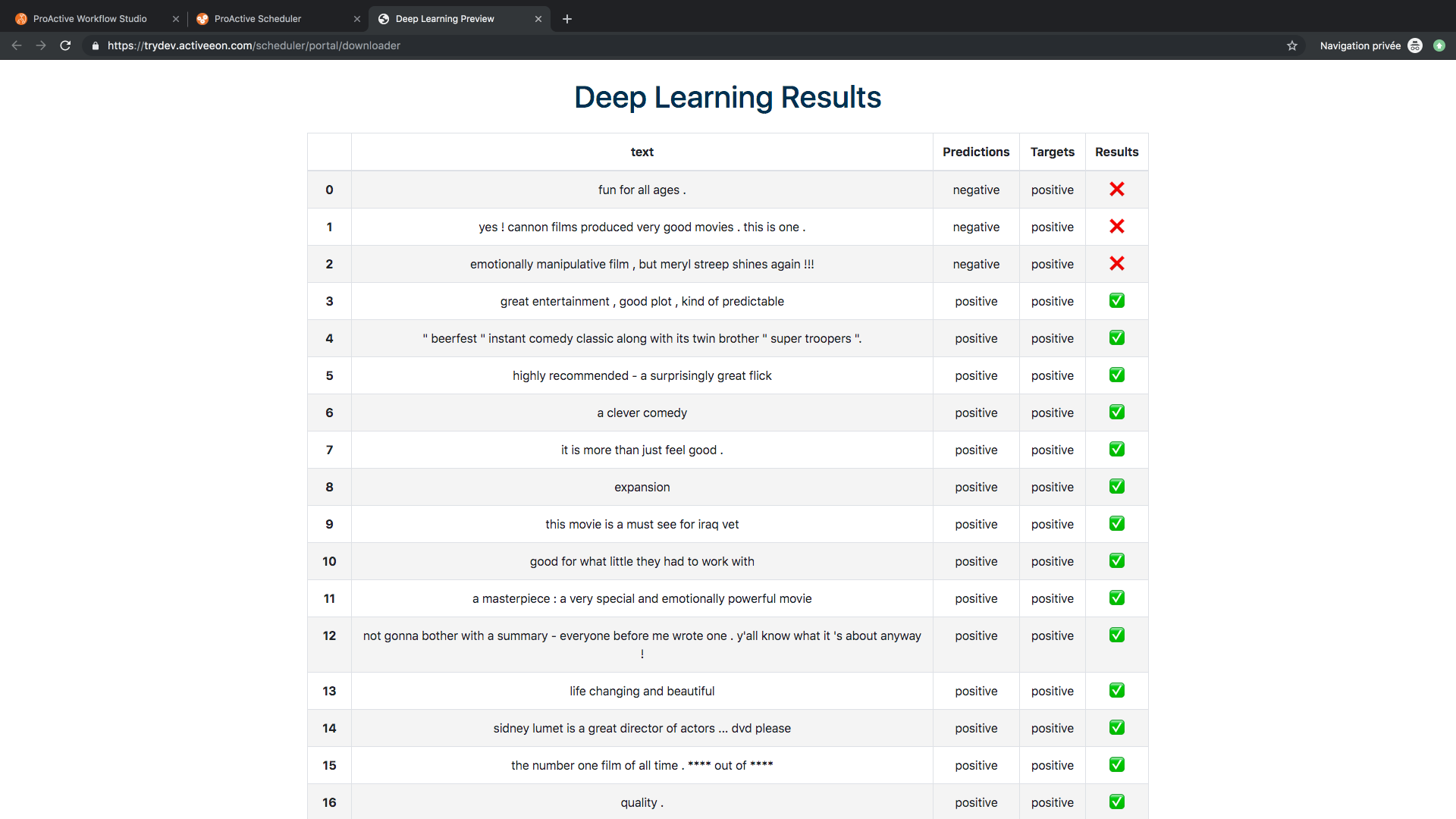
- Click on the Preview_Results task then click on preview then click Open in browser to visualize the prediction results and compare them with the correct labels.
- watch PAIO demo video
- the tutorial on machine learning workflows
- go through our documentation for more details