ProActive Quickstart APIs walkthrough
In this chapter we will present the different ProActive APIs: Scheduler API, Dataspace API, Synchronization API and REST API.
1 Scheduler API
Task Scheduler API can be used inside ProActive Task to interact directly with the scheduler server. This functionality is called Re-entrance. Task Scheduler API:
- is provided as a script binding named schedulerapi (a Java object).
- can be used only inside Java-compatible languages such as groovy, jython, jruby, scala. Can also be used in cpython.
The API can be used for example to submit jobs stored in the ProActive Catalog, build workflows manually using the workflow API, killing jobs, etc...
Let’s illustrate the scheduler api with an example: Create a new job with a single groovy task. Inside the task, enter the following code:
Let’s modify the previous workflow to wait for subworkflow termination. Edit the previous code:
Task Scheduler API can be used in certain scripts only, for more info: https://doc.activeeon.com/latest/user/ProActiveUserGuide.html#_variables_quick_reference.
2 Dataspace API
Let’s imagine the following use case, the workflow Image Processor:
- Image Processor list all JPEG files located in the user space, this is done by a List Task.
- For each image file, it will execute a Processing Task operation on the file. Processing will occur on multiple machines.
To resolve this kind of use-case, the Task DataSpace API comes very handy. Here are the main features:
- Task DataSpace API can be used similarly as Task Scheduler API.
- It connects to either the User Space or the Global Space and allows to list, download, upload or delete files.
- The API is defined here: https://doc.activeeon.com/latest/javadoc/org/ow2/proactive/scheduler/task/client/DataSpaceNodeClient.html.
To illustrate this, drag'n drop the Replicate workflow from the bucket Controls.
Rename the Split task to List_Task.
Replace its implementation code with this groovy script:
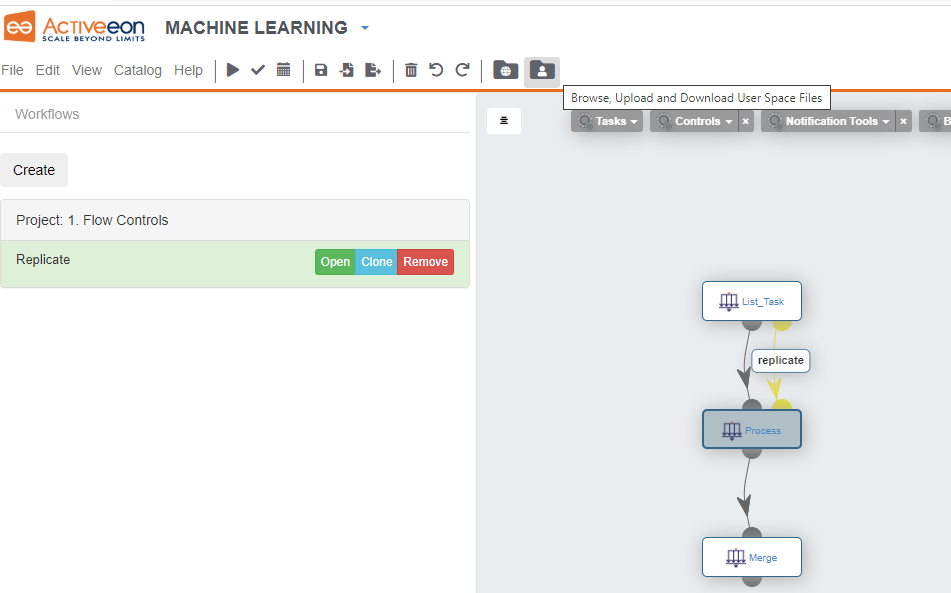
And upload your files.
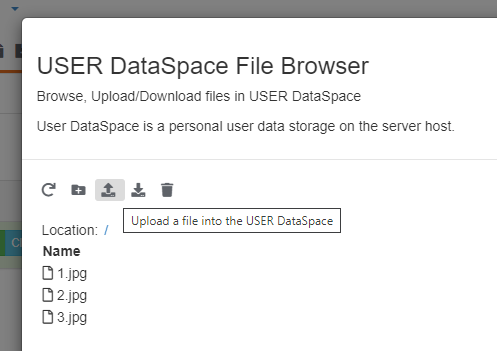
Run the workflow and observe how it dynamically creates tasks to process images.
Here, each task stores an image and makes it accessible using the result and resultMetadata objects.
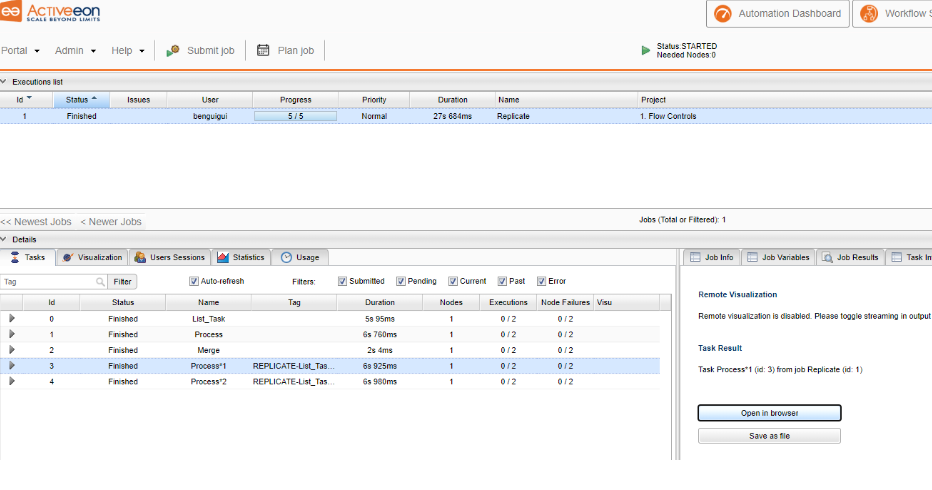
From the scheduler portal, click on a terminated Process task.
Under the Task Preview tab, you can either open the result (here the image) and simply download it.
3 Synchronization API
Task synchronization is traditionally handled by the ProActive Scheduler through Task
Dependencies.
Task Dependencies does not allow fine grain synchronization (for example between
sibling task or across multiple workflows).
Task Synchronization API is the tool to use when complex synchronization patterns
are needed.
Task Synchronization API works as a key-value store organized in channels.
Each channel has a unique identifier name, each channel is a HashMap.
This means that each put operation is identified by a 3-tuple:
The synchronization service is started with the scheduler automatically.
Channels can be made persistent (preserved at scheduler restart) or kept in memory only.
Each channel is implemented internally as a Java HashMap, all methods defined in the Java 8 Map interface can be used, with some signature changes.
Importantly, all lambda-related methods allow to perform operations on the map instead of simply replacing entries.
A key point is that all operations on the synchronization API are atomic. In other words, two operations coming from two different tasks, do not run concurrently.
In addition to methods provided in the Map interface, wait methods are implemented, this allows for example to block a task until a certain condition on the map occurs.
When lambdas are used, they must be passed as string values defining a Groovy closure. This is to ensure language interoperability (a python script can thus use the Synchronization API with lambdas).
For example :
Documentation : https://doc.activeeon.com/latest/user/ProActiveUserGuide.html#_task_synchronization_api.
JavaDoc for Synchronization API: https://doc.activeeon.com/latest/javadoc/org/ow2/proactive/scheduler/synchronization/Synchronization.html.
Let's illustrate this mechanism by a simple workflow. Create an empty workflow and select the Key_Value workflow under Controls->Synchronization API Examples
The implementation code of the Init task:
4 REST API
The REST API web page: https://try.activeeon.com/rest.
Examples of the REST API usage in the tutorials, such as: https://try.activeeon.com/tutorials/quickstart/quickstart.html.